

Las computadoras trabajan con números, no entienden otra cosa. Por eso el invento más fabuloso de este siglo, la IA Generativa, tuvo que utilizarlos para generar las palabras con las que nos hablan las inteligencias artificiales.
En la actualidad hay diversos sistemas y los mas reconocidos son: ChatGPT (de OpenAI), Gemini (de Google), DeepSeek (que cambió el juego de la IA desde China), la IA Meta (que tenemos en WhatsApp), Grok (la de Elon Musk que esta integrada en X), y Claude de Anthropic,
Todos ellos se basan en modelar el lenguaje, es decir en replicar su comportamiento mediante una serie de pasos que los transforman en números y operaciones matemáticas.
Como lo mejor es comenzar por el principio aquí vamos a descubrir una técnica que transforma las palabras para que puedan ser entendidas por los algoritmos de computación.
Desde chicos notamos ciertas similitudes entre las palabras porque se pronuncian parecido o por su significado. Tenemos una idea intuitiva de que ciertas palabras están mas cerca que otras. Y estar cerca, implica alguna forma de medición, por lo tanto debiera haber alguna forma de "matematizar" las palabras para poder compararlas.
Esa fue la gran aventura de los "embedding" esto es la técnica que se desarrolló para transformar las palabras en números. Y su descubrimiento fue todo un viaje hacia las profundidades del lenguaje.
Sin hacer todo el recorrido histórico que ya comienza en los años 50, se llegó a un momento en que había muchísimos palabras digitales disponibles y una nueva frontera técnica que venía avanzando con fuerza: las redes neuronales. Se tenía una idea concreta: una palabra podría representase no por un número, sino por un vector, esto es un conjunto de números.
En nuestro mundo lo podemos ver porque el espacio que ocupamos se representa por un vector. Se dice que estamos en un espacio de tres dimensiones porque necesitamos tres números para ubicarnos, o sea si hacemos un pedido a través de la App de Rappi tenemos que dar tres datos: calle, número y altura (ej French, 3160, Piso 2d). Vivimos entre vectores de tres números.

Si representamos la palabra "Gato" por un vector, podríamos capturar su multidimensionalidad semántica: que es un animal, que salta, que es un sustantivo, que tiene cuatro patas, que es una mascota, etc. O sea a medida que aumentamos la dimensionalidad mas podemos caracterizar al gato. Y entonces otras palabras como perro comienzan a estar "cerca". Perro también es un animal, también es un sustantivo, también es una mascota.
En la escuela aprendemos a capturar dimensiones para las palabras: verbo, sustantivo, adjetivo, adverbio, etc. Son unas 8 o 9 dimensiones según las que se considere. Ahora eso llevado al ámbito de la computación nadie sabia cómo traducirlo. O sea cómo definir que deberían representar cada una de las coordenadas numéricas.
Entonces lo que hicieron fue definir un número de dimensiones, por ejemplo 50, con lo cual habría 50 números asociados a gato, mucho más que las que aprendemos en la escuela, y dejar que la red neuronal aprenda sola que valores númericos poner. Comienza al principio llenando esos números al azar, y luego a medida que se alimentaba con textos va descubriendo qué palabras aparecían cercanas o relacionadas en esos textos, y así va cambiando esos números. Y asi en múltiples veces el modelo internamente va ajustando los valores de los "embeddings".
En realidad, no se sabe cómo el sistema representa este vector gato en esos 50 números o dimensiones. No se sabe si la primer coordenada es que es un animal, la segunda una mascota, la tercera el género, etc. Lo que si en algunos contextos puede hacerse es una especie de ingenieria inversa, y a partir de cómo armó ese vector darse cuenta que algunos componentes representan cosas obvias como las mencionadas.
La elección de qué esta haciendo la red neuronal es completamente automática y no es explícita, quizá captó cosas que ni siquiera nosotros interpretamos. Se trata de una visión absolutamente pragmatista, simplemente funciona, y si funciona algo debió captar sobre la naturaleza de las palabras.
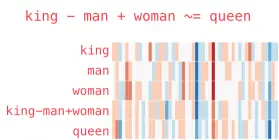
Y aquí llegamos al tema: los embedding son esta forma de traducir las palabras en vectores (o sea una secuencia de números), para que luego se puedan comparar palabras entre sí. La magia que sorprendió a los investigadores fue que si uno toma los números que representan a Rey y les resta, coordenada a coordenada o sea en el mismo orden, los númerpos que represan a Hombre, le da otro vector que está muy cerca del que representa a Reina. ¿Fascinante, no?
El algoritmo con el que explotó este tema se llama word2vec y fue creado en Google, por un equipo que lideraba Tomas Mikolov en 2013. Como resultado, las representaciones vectoriales de las palabras (los embeddings) capturaron las relaciones semánticas y sintácticas entre ellas.

La historia luego continuó con una generalización de la idea: ya no se trata de hacer un embedding estático de la palabra Gato, sino que este sea dinámico, que esa especie de firma digital de las palabras pueda cambiar de acuerdo a la frase en que esta la palabra. Así banco puede ser un lugar para sentarse (un tipo de embedding con su propia serie de números que lo representa) o la institución bancaria (otro embedding). Cambia el embedding de cada palabra de acuerdo al contexto en el que se haya.
El gran este avance de word2vec, un algoritmo que estuvo disponible a desarrolladores de todo el mundo para que puedan innovar, encendió el camino que abrió las puertas al descubrimiento de la IA Generativa. Tomás volvió a la República Checa, y se puede ver en su linkedin como en su propio país le falta el reconocimiento que merece, y con ellos los fondos necesarios para sus investigaciones. Estas líneas tienen el propósito de divulgar su aporte clave para que la nueva era de la IA sea posible.








